4.2 E值:有不可观测混杂变量的观察性实验中的因果性证据
第三部分讨论的所有方法都极其依赖于可忽略性假设. 它们要求控制处理变量和结果变量之间的所有混杂因素. 然而我们无法用数据来验证可忽略性假设. 由于存在不可观测混杂因素, 观察性研究经常受到批评. Yule-Simpson悖论 表明, 一个未测量的二元混杂因素可以完全推翻观察到的处理与结果之间的关联. 然而, 要推翻一个更大的观察关联, 这个未测量的混杂因素必须与处理和结果具有更强的关联 . 换句话说, 并非所有的观察性研究都是生而平等的. 有些研究能比其他研究提供更强的因果证据.
本章从 E 值 开始. 对于使用 Logistic 回归来估计处理对二元结果的条件风险比 (Risk Ratio) 的观察性研究, 它更为有用.
4.3讨论基于结果回归、IPW 和双重稳健估计的平均因果效应的敏感性分析.
4.4 讨论 Rosenbaum 针对匹配观察性研究的敏感性分析框架.
1 Cornfield 型敏感性分析
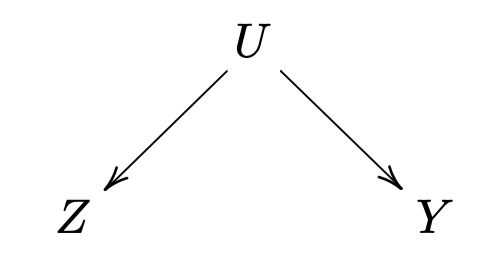
尽管我们不假定给定 X Z ⊥̸ ⊥ { Y ( 1 ) , Y ( 0 ) } | X , X U Z ⊥ ⊥ { Y ( 1 ) , Y ( 0 ) } | ( X , U ) . Y 风险比的真实条件因果效应 和观测到的条件风险比 为
RR Z Y | x true = P ( Y ( 1 ) = 1 | X = x ) P ( Y ( 0 ) = 1 | X = x ) . RR Z Y | x obs = P ( Y = 1 | Z = 1 , X = x ) P ( Y = 1 | Z = 0 , X = x ) . 一般来说, 如果有不可观测的 U RR Z Y | x true = ∫ P ( Y = 1 | Z = 1 , X = x , U = u ) f ( u | X = x ) d u ∫ P ( Y = 1 | Z = 0 , X = x , U = u ) f ( u | X = x ) d u , RR Z Y | x obs = ∫ P ( Y = 1 | Z = 1 , X = x , U = u ) f ( u | Z = 1 , X = x ) d u ∫ P ( Y = 1 | Z = 0 , X = x , U = u ) f ( u | Z = 0 , X = x ) d u , U
回顾 前面的吸烟的例子 . 这里的基因同时导致吸烟和肺癌被称为 共同的原因猜想 . Cornfield 以一个更有建设性的视角看待这个问题, 并提问: 这个未观测的混淆变量需要多强才能否决吸烟和肺癌的关系?X
我们有 Z ⊥ ⊥ Y | ( X , U ) X , U Z , Y X Z , Y U RR Z U | x = P ( U = 1 | Z = 1 , X = x ) P ( U = 1 | Z = 0 , X = x ) , RR U Y | x = P ( Y = 1 | U = 1 , X = x ) P ( Y = 1 | U = 0 , X = x ) . X = x
在 Z ⊥ ⊥ Y | ( X , U ) (1.0) RR Z Y | x obs > 1 , RR Z U | x , RR U Y | x > 1 , (1.1) RR Z Y | x obs ≤ RR Z U | x RR U Y | x RR Z U | x + RR U Y | x − 1 .
这里的假设是不失一般性的.
如果 RR Z Y | x obs < 1 RR Z Y | x obs > 1
如果 RR Z U | x < 1 U → 1 − U RR Z U | x > 1
如果前两者成立, 第三者自动成立.
这个定理给出了观测到的风险比的上界.
定义 f 1 , x = P ( U = 1 | Z = 1 , X = x ) , f 0 , x = P ( U = 1 | Z = 0 , X = x ) . RR Z Y | x obs RR Z Y | x obs = P ( Y = 1 | Z = 1 , X = x ) P ( Y = 1 | Z = 0 , X = x ) = P ( U = 1 | Z = 1 , X = x ) P ( Y = 1 | Z = 1 , U = 1 , X = x ) + P ( U = 0 | Z = 1 , X = x ) P ( Y = 1 | Z = 1 , U = 0 , X = x ) P ( U = 1 | Z = 0 , X = x ) P ( Y = 1 | Z = 0 , U = 1 , X = x ) + P ( U = 0 | Z = 0 , X = x ) P ( Y = 1 | Z = 0 , U = 0 , X = x ) = P ( U = 1 | Z = 1 , X = x ) P ( Y = 1 | U = 1 , X = x ) + P ( U = 0 | Z = 1 , X = x ) P ( Y = 1 | U = 0 , X = x ) P ( U = 1 | Z = 0 , X = x ) P ( Y = 1 | U = 1 , X = x ) + P ( U = 0 | Z = 0 , X = x ) P ( Y = 1 | U = 0 , X = x ) = f 1 , x RR U Y | x + 1 − f 1 , x f 0 , x RR U Y | x + 1 − f 0 , x = ( RR U Y | x − 1 ) f 1 , x + 1 RR U Y | x − 1 RR Z U | x f 1 , x + 1 . RR Z Y | x obs f 1 , x f 1 , x = 1
在上面的证明中我们得到一个恒等式 (1.2) RR Z Y | x obs = ( RR U Y | x − 1 ) f 1 , x + 1 RR U Y | x − 1 RR Z U | x f 1 , x + 1 . { f 1 , x , RR Z U | x , RR U Y | x } { RR Z U | x , RR U Y | x } (1.1) 强. 但是 (1.2) 包含了更多的参数, 所以我们面临了一个取舍, 是要更高的精度 ((1.2)) 还是要更方便的分析 ((1.1)).
2 E 值
定义 β ( ω 1 , ω 2 ) = ω 1 ω 2 ω 1 + ω 2 − 1 ω 1 > 1 ω 2 > 1
β ( ω 1 , ω 2 ) ω 1 , ω 2 β ( ω 1 , ω 2 ) ω 1 , ω 2 β ( ω 1 , ω 2 ) ≤ ω 1 β ( ω 1 , ω 2 ) ≤ ω 2 β ( ω 1 , ω 2 ) ≤ ω 2 2 ω − 1 ω = max ( ω 1 , ω 2 )
根据 定理1.1 和引理 (3), 我们有RR Z U | x ≥ RR Z Y | x obs , RR U Y | x ≥ RR Z Y | x obs ⟺ min ( RR Z U | x , RR U Y | x ) ≥ RR Z Y | x obs . RR Z U | x RR U Y | x RR Z Y | x obs ω = max ( RR Z U | x , RR U Y | x ) 定理1.1 和引理得到 ω 2 2 ω − 1 ≥ β ( RR Z U | x , RR U Y | x ) ≥ RR Z Y | x obs ⇒ ω 2 − 2 RR Z Y | x obs ω + RR Z Y | x obs ≥ 0 , 1 ω = max ( RR Z U | x , RR U Y | x ) ≥ RR Z Y | x obs + RR Z Y | x obs ( RR Z Y | x obs − 1 ) . RR Z U | x RR U Y | x RR Z Y | x obs + RR Z Y | x obs ( RR Z Y | x obs − 1 )
如果观察到条件风险比 RR Z Y | x obs E 值 为 RR Z Y | x obs + RR Z Y | x obs ( RR Z Y | x obs − 1 ) .
E 值是为参数 RR Z Y | x obs RR Z Y | x obs RR Z Y | x obs FRT ). 但是在样本量巨大的观察性实验中, p 值就可能表现很糟糕了. 即使因果效应真的为 0 E 值是观察性研究中因果效应证据的更好指标 .
3 扩展讨论
3.1 E 值和因果性的 Bradford Hill 标准
E 值为因果性提供了证据, 但证据不是证明. 大的 E 值下, 我们需要更强的未观测混杂变量来否决观察到的风险比, 因此本身因果的证据更强; 反之小的 E 值下, 我们需要更弱的未观测混杂变量, 因果的证据更弱.
Strength (强度): E 值
Consistency (一致性): 结论能否复现
Specificity (特异性): 一对一精准打击
Temporality (暂时性): 原因必须发生在结果之前
Biological gradient (生物学梯度): 剂量-反应关系
Plausibility (合理性): 业务逻辑/科学机制上说得通
Coherence (连贯性): 不与客观事实规律冲突
Experiment (实验): 随机化实验
Analogy (类比): 之前有过类似的成功经验
E 值可以用来说明他的第一条标准: 更强的联系通常提供更强的因果性 , 因为要否决更强的联系, 我们需要更强的混杂变量. 而第二部分随机化实验则说明了他的第八条标准.
3.2 Logistic 回归后的 E 值
如果结果是二元的, 流行病学家们就可以用 Y i Z i , X i P ( Y i = 1 | Z i , X i ) = e β 0 + β 1 Z i + β 2 T X i 1 + e β 0 + β 1 Z i + β 2 T X i . Z i β 1 = log P ( Y i = 1 | Z i = 1 , X = x ) P ( Y i = 0 | Z i = 1 , X = x ) P ( Y i = 1 | Z i = 0 , X = x ) P ( Y i = 0 | Z i = 0 , X = x ) P ( Y i = 1 | Z i = 1 , X i = x P ( Y i = 1 | Z i = 0 , X i = x ) 0 β 1 ≈ log P ( Y i = 1 | Z i = 1 , X i = x ) P ( Y i = 1 | Z i = 0 , X i = x ) = log RR Z Y | x obs .
3.3 非零真实因果效应
定理1.1 假设实验对结果没有真的因果效应, 即 RR Z Y | x true = 1
修改定义为 RR U Y | x = max z = 0 , 1 P ( Y = 1 | Z = z , U = 1 , X = x ) P ( Y = 1 | Z = z , U = 0 , X = x ) . (1.0) 成立. 我们有 RR Z Y | x true ≥ RR Z Y | x obs / RR Z U | x RR U Y | x RR Z U | x + RR U Y | x − 1 .
定理 1.1 是它在 RR Z Y | x true = 1 1 1 RR Z Y | x obs
4 一些批评和回应
4.1 E 值只是风险比的单调变换?
这是部分正确的. 但是更重要的是它解释了: 为了否决观测到的风险比, 混杂变量至少要和 E 值一样大.
4.2 E 值的校准
E 值依赖的混杂性本质上是潜在的, 我们没办法直接决定一个 E 值是大还是小. 另一个问题是 E 值取决于我们已经控制了多少 X X = ( X 1 , ⋯ , X p ) X j Z − X j X j − Y
4.3 对二元结果和风险比效果最好
其他的方法不如二元结果那么优雅. 下一章我们会介绍一种简单的敏感性分析方法, 可以包含结果回归、IPW、双重稳健估计量.